large language models in SE

2025-07-29
Intro Exercise
- Take the sample problem, and with your partner, solve it with ChatGPT/Copilot.
- Now add some tests to that code.

Discussion
In your team, please discuss the following. We will then go thru each pair in turn to discuss the questions.
- How does it know what identifiers to use?
- What is it using to suggest Command pattern completions?
- What is the natural part of this code? What is the complex piece?
- What would you want a human rater to improve?
Large Language Models for Software Engineering
What Did We Do Before
How did “AI” help in Software Engineering tasks in the past?
What are we training on?
- Textual data
- Sources?
- Other approaches? ASTs?
Tasks for LLMs
As we will see, one way to think about a language model is that it can solve a task like: 1
- Prediction/Masking: what replaces 🔡 in “Jim drove a 🔡 to the Drive-Thru line” (masking). Commonly used for self-supervision in training.
- Analogy: “Red is to rose as 🔡 is to iris”
- Question Answering: “who was president of the USA in 2002?”
Tasks for LLMs
- Winograd Schemas: The city council refused the demonstrators a permit because they [feared/advocated] violence.
- Translation: “j’aime beaucoup la cuisine japonais” in English is … (taking into account colloquialisms, idioms, slang etc.) “I like very much the cooking Japanese”
- Summarization: what does
System.out.println("neil is an awesome instructor")do?
Mentimeter / Quiz discussion
Naturalness
Source code is a language!!
Complete:
System.out.println( ...Complete:
My cat has three ... Useful terms
- N-gram - N tokens in a group. Bigram: “hot lunch, big fish” Tri-gram “Manchester United won”
- Token - an atomic “chunk” in the corpus. Could be a word; could be a source code token (
{). - Stop words - words we don’t think will be important. Typically, “the, an, and, or” (but which ones?)
Useful Terms (2)
- Stemming/lemmatization - shorten words to their essence. “Skillfully” -> skillful- / skill-
- Language Model - for a set T of tokens in a vocabulary, map a probability distribution \(p(.)\) to sets \(S\) of tokens in \(T^*\)
- AST - Abstract Syntax Tree. A way of representing (encoding) programs using symbols and relationships.
Useful Terms (3)
- Distance: historically ML has had a hard time understanding concepts separated in text. But this happens a lot in source code (
var theVar; ... ; theVar = 5;). Need something to represent this span of relationship. - OOV: out of vocabulary, a word that is not in the vocabulary (dictionary) learned in the model’s training. E.g., a word that does not appear in Wikipedia, for the GloVe embedding. Such a word will have no representation (think about a self-driving car seeing a totally novel situation like a helicopter landing on the freeway).
Tokenizing
Convert text into numeric representations of the text. Remember that in training we will be using these tokens billions of times.
Try out https://simonwillison.net/2023/Jun/8/gpt-tokenizers/
Simple model: N-grams
Create a language model by effectively counting how often a particular set of n tokens occurs. For example (from the Hindle paper):
\(p(a_4|a_1a_2a_3) = \frac{count(a_1a_2a_3a_4)}{count(a_1a_2a_3*)}\)
Measure success by log perplexity, or cross-entropy:
\(H_{\mathcal{M}}(s) = - \frac{1}{n} log~p_\mathcal{M}(a_1 ... a_n)\)
Building an n-gram model
With your project team, build a simple n-gram model for answering Jeopardy questions. I’ve uploaded a sample you can use on Teams.
- what did you expect to be the case?
- what value of N worked best? what is hard about Jeopardy?
- try one of the sample questions with an LLM like Copilot. Does it do better? Why?
- add a perplexity scoring mechanism
- what types of tests or evals should you be trying?
Encoding
After preprocessing, we need to encode the tokens - a word like “function” - into a numeric representation.
- Count embedding: each word is represented by its frequency
- TF-IDF - represent using a ratio of how common a token is to its inverse document frequency
Encoding
- Word embedding: Each word is encoded into a vector (rank 1 tensor) of real numbers representing different dimensions (often 100, 200). E.g.,
function=[0.322, 0.113, 0.567,..]. Importantly, words that “mean” similar things (for our domain of interest) should be closer together on some distance metric.
Reuse
- Most of the time we can re-use embeddings
- Careful that the source data is close to our data (e.g., the train control system might not be represented by Wikipedia).
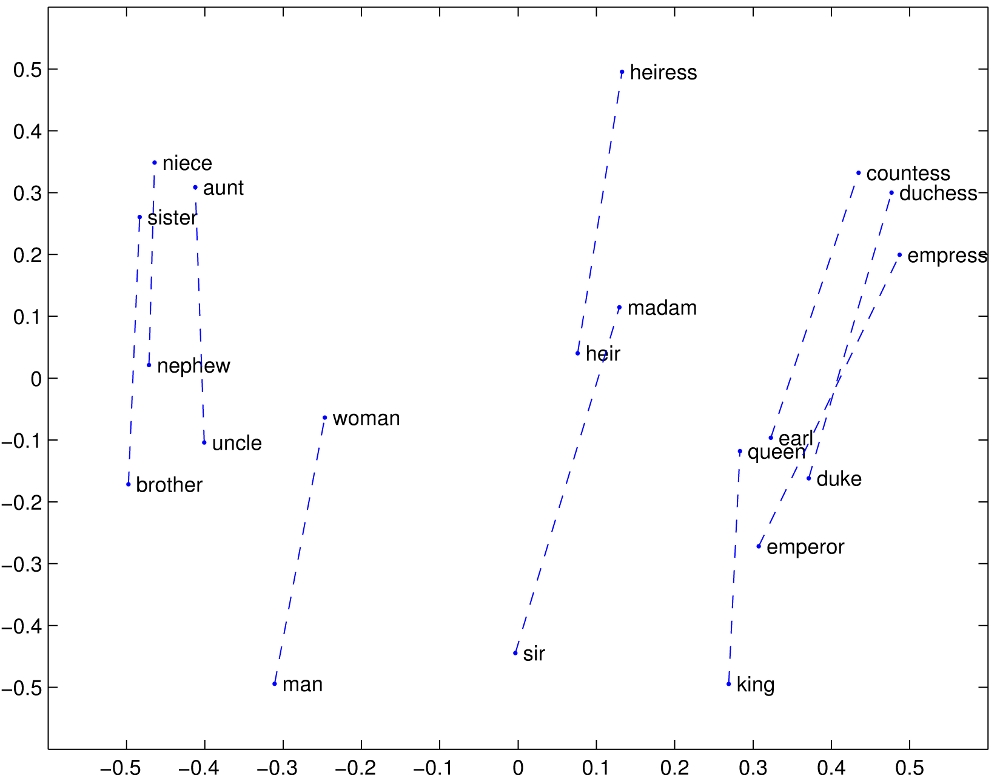
This works OK … but language is pretty complicated.
The word embedding model is restricted to looking a few tokens ahead or behind (the window/context).
That means learning more complex relationships (e.g., this phrase modifies a previous noun) are hard to do.
Break
Can we improve on these approaches?
Attention and Transformers
Another approach is to use deep learning via attention mechanisms in transformer models. This is how BERT, GPT4, T5 etc work.
Digression: supervision.
Supervision is when a human labels or validates the machine’s results.
- Fully supervised = humans provide a complete, labeled dataset.
- Unsupervised - there is no label, the machine just tries to clump similar things together.
- Weakly supervised: the human annotates a few important instances to bootstrap the machine.
- Self-supervised: the machine manipulates the data to “hide” various pieces in order to train.
- Masking is a self-supervised training approach.
Transformers
A transformer is a ML architecture that encodes an input and decodes output:
![]()
Drilling in:
![]()
Attention
Earlier we discussed the problem of sliding windows. Attention is a way to make the model ‘remember’ what it saw before.
attention example from jalammar
Reinforcement Learning with Human Feedback (RLHF)
Get low-paid gig workers to solve the knowledge acquisition bottleneck.
From https://huggingface.co/blog/rlhf:
RLHF
the policy is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over text). The action space of this policy is all the tokens corresponding to the vocabulary of the language model and the observation space is the distribution of possible input token sequences, which is also quite large given previous uses of RL. The reward function is a combination of the preference model and a constraint on policy shift.
What other RLHF approaches have you been subjected to?
RLHF Process
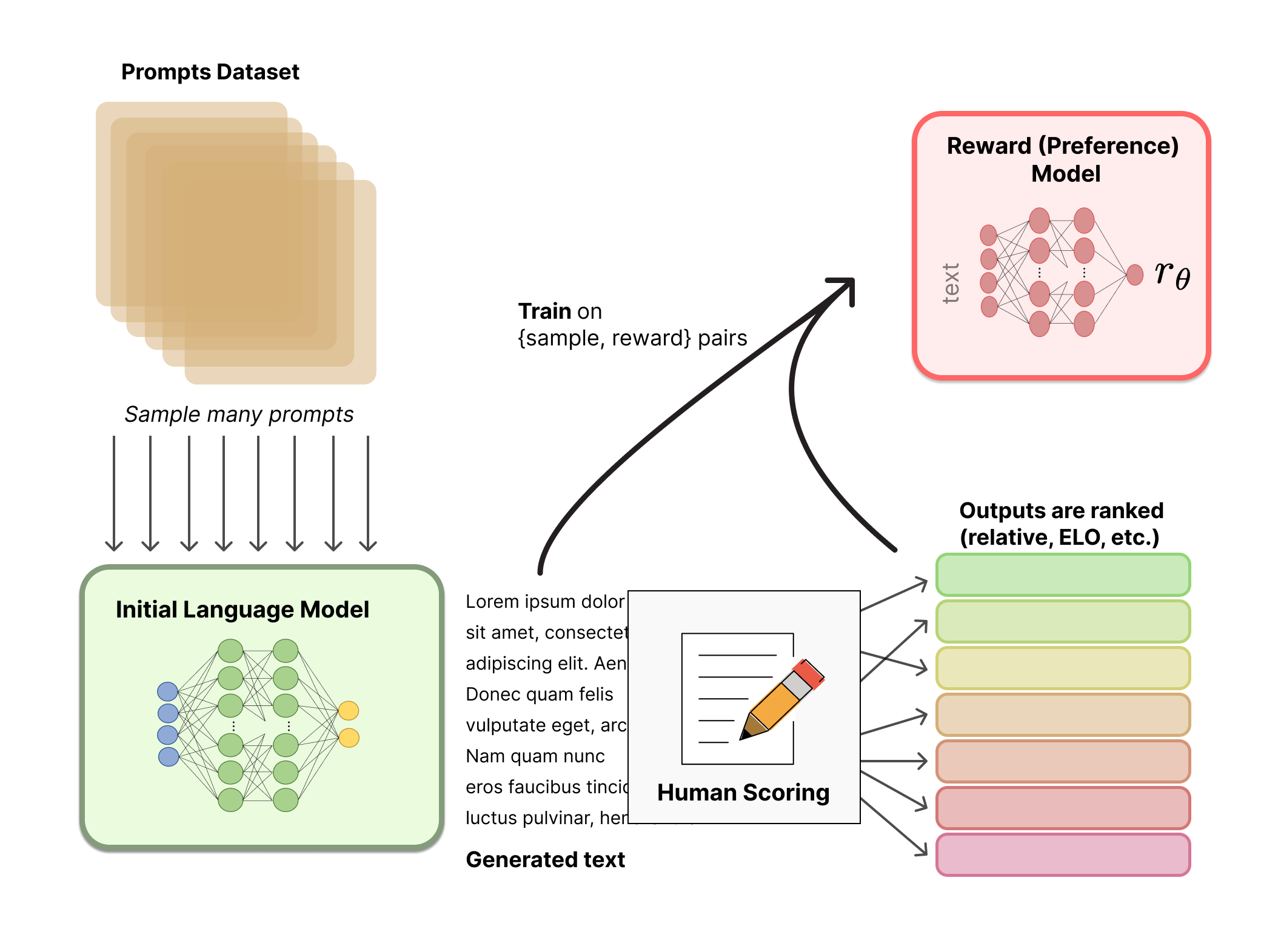
source: https://huggingface.co/blog/rlhf
Validation approaches
What constitutes a good test for LLM coding?
Challenges
Test set pollution: we have to assume the training data includes problems from online (e.g. LeetCode)
Discuss: “match-based metrics are unable to account for the large and complex space of programs functionally equivalent to a reference solution”
What languages and programming problem types should be in the test set?
Sources and Further Reading
- https://peterbloem.nl/blog/transformers
- https://colab.research.google.com/drive/1B_5ow3rvS0Qz1y-KyJtlMNnmgmx9w3kJ#scrollTo=1QOuke5yS3mc
- https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
- https://jalammar.github.io/illustrated-word2vec/
- https://towardsdatascience.com/attention-is-all-you-need-discovering-the-transformer-paper-73e5ff5e0634
- http://jalammar.github.io/illustrated-transformer/
- Lambert, et al., “Illustrating Reinforcement Learning from Human Feedback (RLHF)”, Hugging Face Blog, 2022.
- https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/

Neil Ernst ©️ 2024-5