In Class Slides
2026-06-23
May 13: Intro and AI4SE
Plan
- short class to go over the syllabus and operating approach.
- admin notes
- set up and tooling
Intro
nernst@uvic.ca
Assoc Professor in Computer Science
Acting BSeng Director
ECS 560
Check in/attendance/roll call
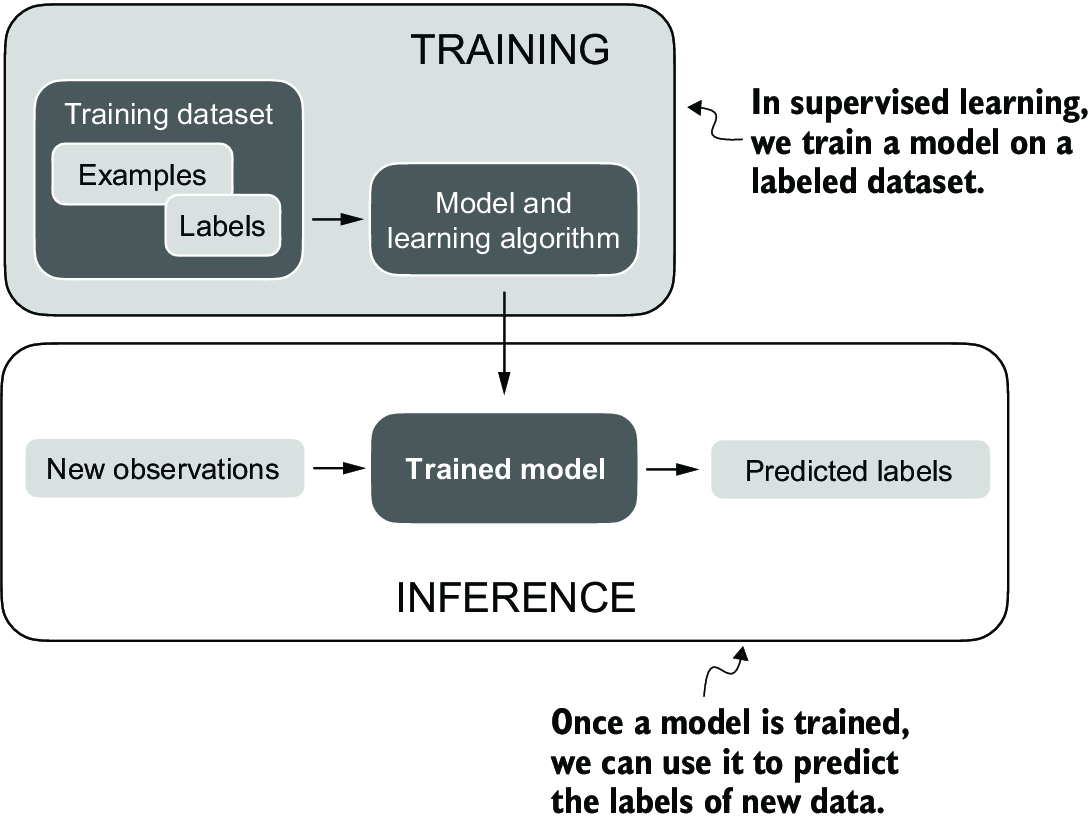
Data Science for SE
This course is about applying Data Science to software engineering data. Data science is a broad term, but I will use it to describe using analytical techniques to support decision making. It combines hacking, statistics, domain expertise, and problem solving.
Syllabus
Updates? New topics?
Project in 6 weeks. Plan accordingly!
The syllabus is our contract. I won’t change things like mark distributions or assignment types, but I can change what we cover and when.
I’m looking for feedback on the topics we are covering, especially the latter part of the term.
Class structure
I hope to minimize the amount of talking I do in favor of exercises. But that means two things on your end:
- Do the readings and setup before class.
- Come with the right equipment - laptops mostly - to class. Let me know if this is a hardship for you privately.
- Each in person class will have an attendance exercise to hand in.
Project and accommodation
Project: the project was previously over 13 weeks. It is now half that time. Thus it will require a lot of work in a short period of time. Plan accordingly!
Accommodations: make sure CAL has your letters so I can adjust accommodations as necessary. If you can, let me know if there are other accommodations you may need beyond extended time.
Slides and Course Website
The format for the slides
Exercise: Icebreaker
Project Overview
Menti
Activity: Setting Up R, RStudio, AI tooling
We will now spend some time getting the basic tooling for this class installed.
May 15: AI4SE
Checkin Question
On a piece of paper1, write one or two points about what plausible implies when it comes to LLM-generated code.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Outline
- Groups and AI tools
- Evals
- Skills
- Plausible Code Paper
- Simple DS with AI exercise
Announcements
- Vancouver seminar
- Assignment 1
AI tools
- What tools are people using for software development? Early 2026 table
- See SWE-Bench leaderboard.
- Short demo of my workflow
Group formation
Organize by topic areas:
- natural language analysis
- human - AI collaboration
- agent evaluation (fixes, time, quality)
- code review (process, duration)
- velocity and productivity
- code analysis (clones, complexity, docs, tech debt)
- refactoring (failed merges, size, difficulty)
Thoughts on readings
What was one takeaway from the readings/videos? Write this down by yourself. Then turn to your neighbor and see what they thought.
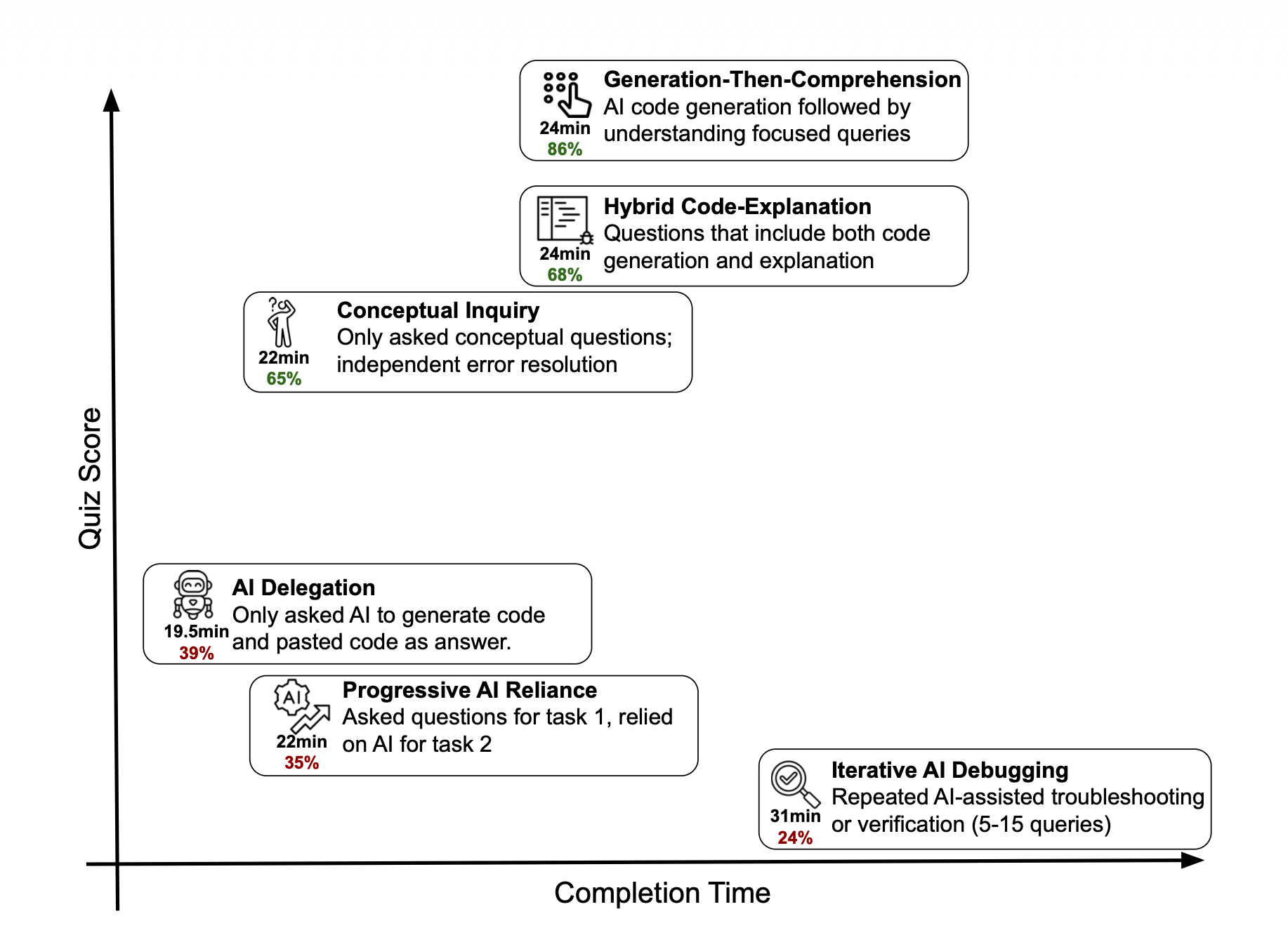
Context Venn Diagram and Effective AI in undergrad
{kind=link}
{kind=link}
Eval Exercise
- Install and Configure PromptFoo.
- Select your preferred AI tool.
- We are creating a system that will use an LLM to give us updated information on how to use MongoDB.
- Create 2 capabilities the LLM should give users, two prompts users might ask, and the PromptFoo validation criteria using assertions.
- Then run this example.
BREAK
PDD Article
With a colleague, select a quote to challenge (disagree with) and a quote to affirm (agree with) from the PDD article. How does this workflow relate to your previous approaches, co-op experiences, or known best practices?
Skills Exercise
Create a skill for your AI agent following the demo at https://agentskills.io/skill-creation/quickstart
Skills Repository
We’ve seen how skills work. I’d like you to go to the Claude skills repository and install a useful skill for your project. For example, there is a research skill and a bibtex editing skill.
Deploy that into your machine following the instructions, and give a prompt that enables the skill.
Exercise: Use LLMs
We will do what Andrej Karpathy calls “vibe coding”: a zen-like use of autocomplete to try and get the AI to do something useful.
Kent Beck has this nice model of how this works. You add features, hurting modularity, then get the modularity - the options - back.
Exercise: Steps
- Download this data file: https://github.com/datasciencedojo/datasets/blob/master/titanic.csv
- Setup an AI tool. I am showing
gemini. - Get the AI to parse the data file and show simple descriptive stats in an R notebook.
- Display the graph.

qr code for titanic data
May 20: Early Approaches
Checkin Exercise
On a piece of paper1, list the biggest change in software engineering you have come across.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Goodhart’s Law
Get into your project groups. If you do not have a group, now is the time to add yourself to one!
As a group, come up with one example of Goodhart’s Law in action. Ideally in software engineering, but any example could work. What is the outcome of this process?
Exercise: Team metrics
QR Code

sonar cloud qr code
go to tab main, then measures, then complexity
SQ Steps
Visit https://sonarcloud.io/summary/new_code?id=mediawiki-core and explore the data science dashboard there.
- Q. what is the part of the code that needs attention? How do you know this?
- Q. what do you make of “issues”? Where do you start with a remediation project?
TPS
- think about the following question: “You are the software engineering manager or team lead at a big company. What is one key question you want to know the answer to for effectively running your team”.
- Write down a quick answer you have - maybe from your past experience.
- Then pair with your table partner to share and discuss their answer and yours. We will then collect a few responses from the class as a whole.
May 20: Problems
Power Analysis
Key concepts: power, effect size, sample size, alpha
Effect size: what is an effect size in the software context?
What are typical sample sizes in SE papers?
Example - R code
Load the two sample files (check Teams) into R, and run a t-test to evaluate the hypothesis that AI makes developers faster. Make sure to print out the descriptive stats first.
Sampling Exercise
Design a sampling strategy for the following question:
- You are the manager of 10 teams at Spotify doing software development. Each team uses their own tools; some use Slack, others use email and IRC. Is there a connection between Slack use and team reported productivity?
and
- You are looking to see how many bugs exist in primarily machine-learning software (e.g., building and training ML models with Tensorflow) vs other types of software
1
Spotify Exercise
You are the CTO at Spotify, concerned that your big AI investment is not being used. How can you measure the extent to which your developers are using AI, and whether it is a useful tool for them?
May 20: Data Mining Basics
Converting Dataframes

link to data
Take some time and convert the jm1 dataset to long form. Hint: the long form is of the form ‘id, variable, value’ and values have to be compatible. (I.e. there are only 3 columns total).
Long forms are usually more useful for data wrangling purposes.
Filtering and Aggregating
Let’s say we are interested in how well Halstead complexity predicts defects.
What is Halstead complexity? What are these complexity metrics in general? Do some research with your partner.
What do you think about the utility of these metrics?
Fitting Distributions
What distribution fits the data set? Hint: this is sometimes done with kernel density plots.
Correlation
Furthermore, correlation - aka multi-collinearity - is something we try to remove in regression analysis as it makes the model overly sensitive and possibly inaccurate.
What types of correlation are likely in the data? Hint: think to first principles for the way the metrics get constructed, and how you know source code is created (your “data generating process”).
Exercise: Weka
I like Weka for exploration but for bigger datasets and more extensive experimentation, the command line or a notebook (hence usually Python) is best.
Load your JM1 data into Weka and explore using a supervised classifier. What performance do you get?
Aside: SAVE YOUR EXPERIMENTS! Always record the steps and params you chose for a given exploration. It will save you headaches later. Tools like Data Version Control can help with this.
Defect Predictors
What is a valid baseline for a defect predictor?
May 27 Bayesian Analysis
Checkin Exercise
On a piece of paper1, explain what hierarchical models are and why they are useful in looking at the AIDev dataset.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Plan
- Hierarchical modeling - varying slopes and intercept models
- Marbles discussion
- Probabilistic programming languages
- Priors = choosing
- Bayesian modeling exercises - ICSE demo
- Causal models
Grads - Signup
Jobs in SE
Modeling Hierarchies
- where do hierarchies occur in SE?
- with a partner, look at the AIDev dataset and think about how hierarchical modeling might help.
Marbles
chalkboard
simulation
Summary

PPL slides
Walk thru Bayesian example
What is happening in the code (see Github).

qr code
Exercise: Causal DAG
With a partner, draw a DAG expressing causality in this experiment.
- what are the important constructs (nodes)?
- what influence do constructs have on each other (arrows)?
- what is the ‘dependent’ node(s)?
Priors - How to Choose
June 3: Ethics
Checkin Exercise
On a piece of paper1,
name one ethical implication of moving to GenAI for writing code.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Plan
- Gold/Krinke
- Black mirror / assignment
- Break
- LLMs
Ethics of Mining paper
With your group, spend 10 minutes examining the data source(s) for your project (i.e., AIDEv, SWE-Bench, etc.).
Then use either
- the Gold and Krinke framework, to assess the data source;
- the “Anticipated Currents” in “Standing in The Fire” (p38), to critique your use of AI tools.
to draft the section on ethics for your project report. Take a photo of your notes and commit it to your group’s Gitlab repo.
Black Mirror Exercise
Assignment 2
Assignment 2 is to generate a Black Mirror style movie pitch. We will spend some time in class developing these, and present them next week.
June 3: LLMs
Intro Exercise
- Take the sample problem, and with your partner, solve it with ChatGPT/Copilot.
- Now add some tests to that code.

Command Pattern Discussion
In your team, please discuss the following. We will then go thru each pair in turn to discuss the questions.
- How does it know what identifiers to use?
- What is it using to suggest Command pattern completions?
- What is the natural part of this code? What is the complex piece?
- What would you want a human rater to improve?
Building an n-gram model
Build a simple n-gram model using the sample book text on Teams. I’ve uploaded a sample you can use on Teams. I suggest using the smaller “test.txt” data to speed things up.
Your job:
- modifications: instead of downloading the book, how do we specialize this for source code?
- if the vocabulary of the book is the set of unique tokens in that book, what is a code vocabulary?
- do we care about what index a token is assigned?
- what do we do if we encounter a word that is “OOV”, namely, not in our vocabulary?
- where does this happen in source code? (identifiers)
- special tokens:
, <|unk|>, <|identifier|>
N-gram Discussion
- what did you expect to be the case?
- what value of N worked best? what is hard about word prediction?
- try one of the sample questions with an LLM like Copilot. Does it do better? Why?
- add a perplexity scoring mechanism
- what types of tests or evals should you be trying?
SWE-Bench
Go to this issue: pylint 4551


With a partner, read through the logs of the tool I posted to Teams.
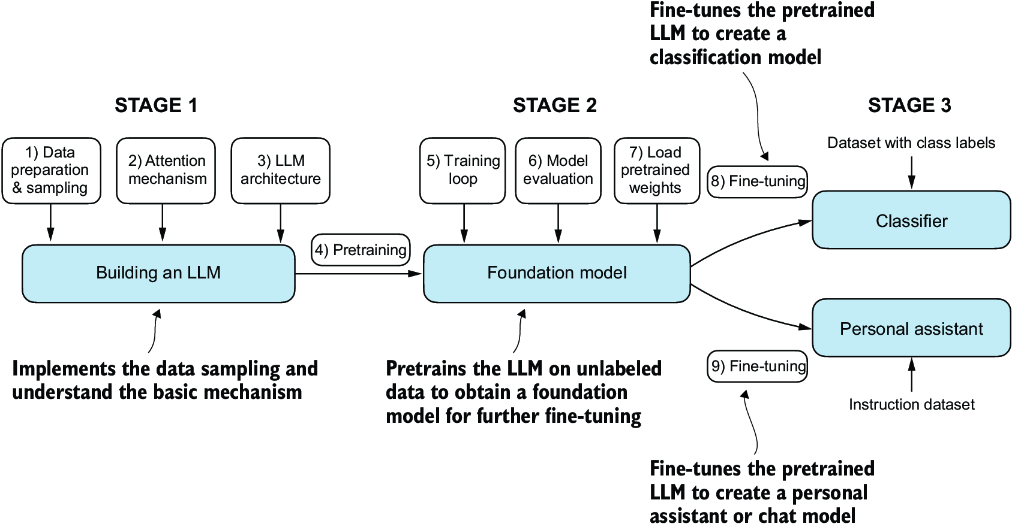
June 10: Build an LLM
Checkin Exercise
On a piece of paper1,
Explain what pass@k is, and why it works (or not) for software tasks.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Plan
- Black Mirror presentations
- Examine / test Raschka code on embeddings and attention
- Learn how to tokenize and embed text
- Create attention mechanisms
- Walk thru Coding Agent code from Raschka
Grad Opportunities
Ch 2 Tokens and Embeddings

BPE with tiktoken
Questions
- why do we use BytePairEncoding?
- what are we going to train on?
- why do we care about positional embeddings?
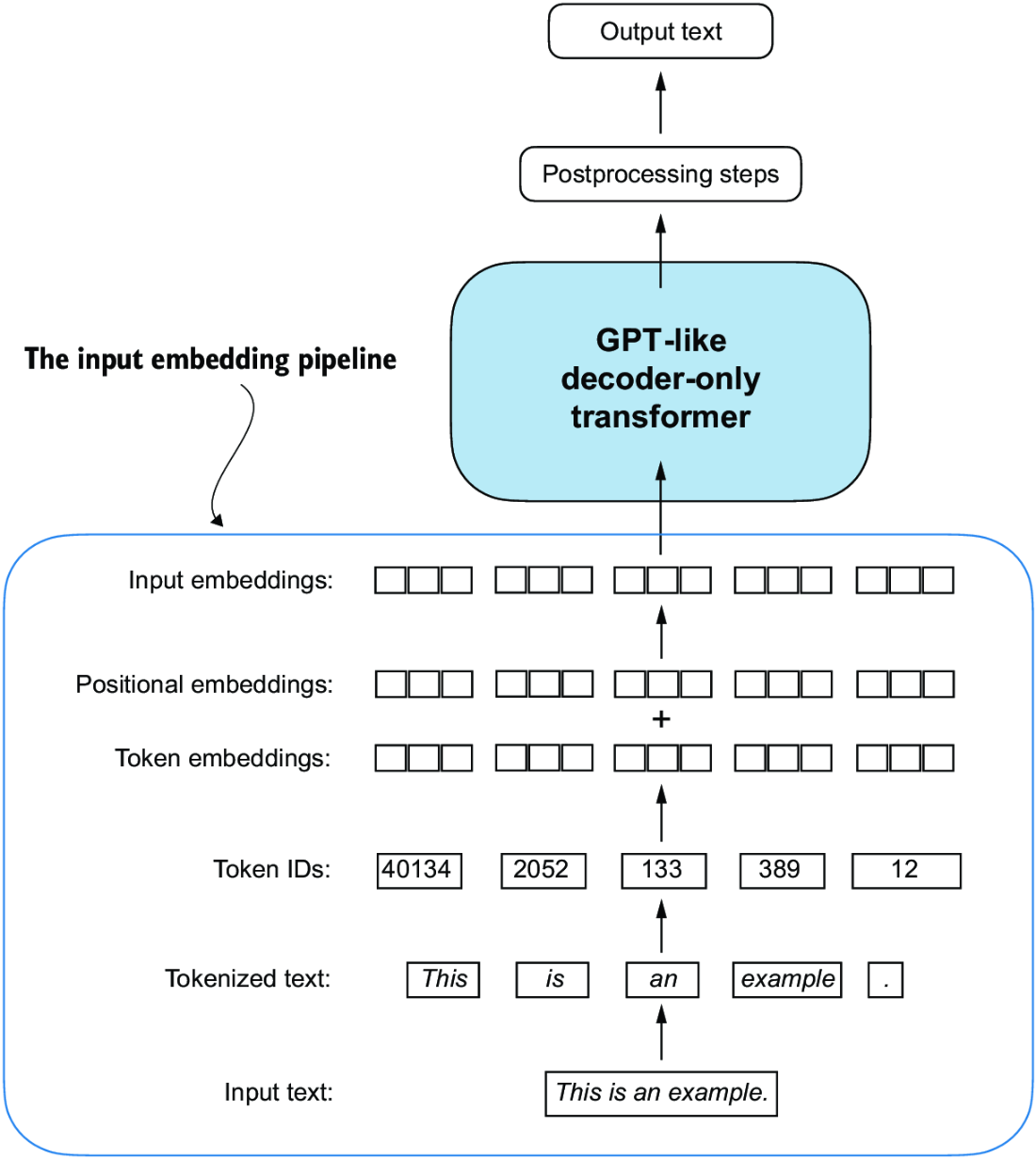
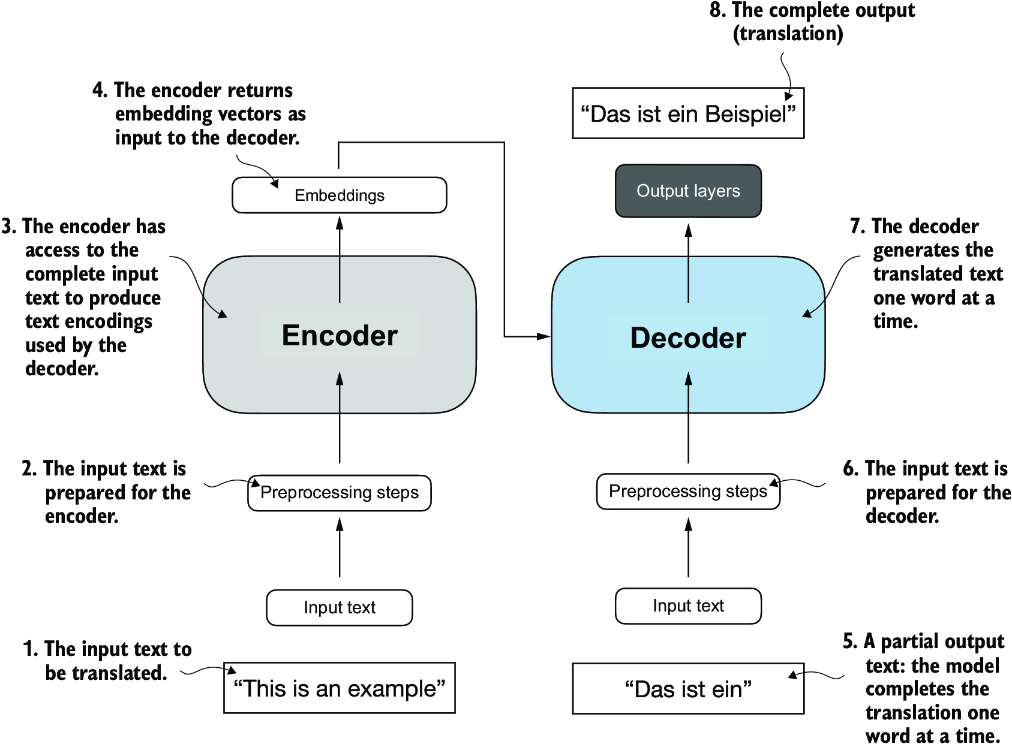
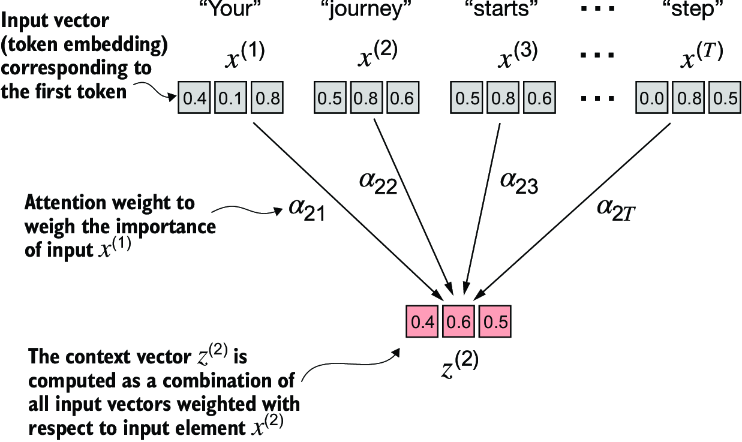
Ch 3 Attention
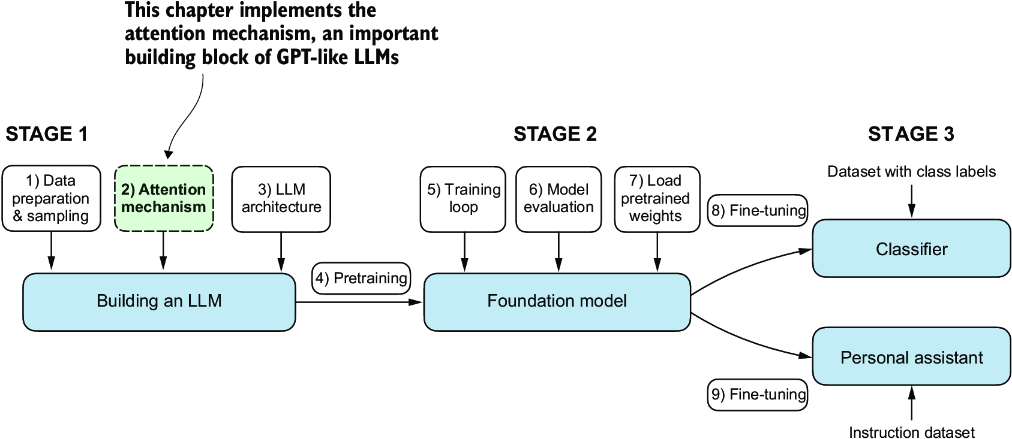
Simplified Self-Attention
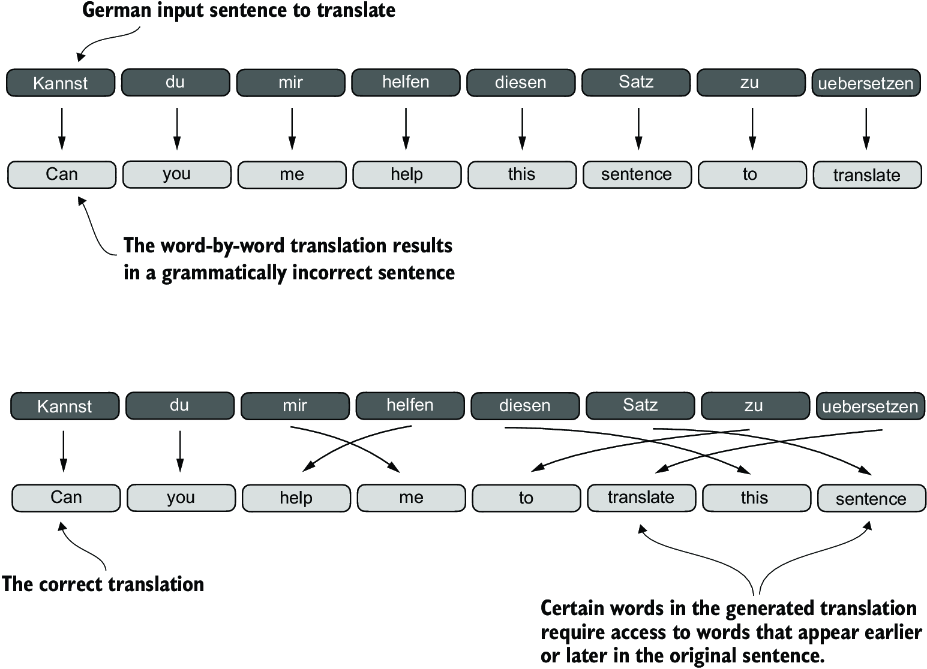
Context Vectors
Query
Weight Matrices
Weight parameters are the fundamental, learned coefficients that define the network’s connections, while attention weights are dynamic, context-specific values.
Training
We set up the model with these representations of (eventually) Queries, Keys, Values.
Our training phase will start predicting next words given the input, and when there’s an error, backprop updates the matrices to improve the results (billions of times).
In inference, we give a query and the model returns the most likely next word(s).
Extending
- add trainable weights
- ignore unseen words by masking
- do this many times
Mini Coding Agent
With a colleague, evaluate the code in this repo.
Take the six components described in the article, and examine the source code implementing those pieces. (see Lines 38-46). Take turns going through the 6 modules, and acting as explainer and questioner.
The goal is to be comfortable understanding how a tool like the mini-agent can make AI chat seem magical.
Answer the question with your colleague: > where is this mini agent going to have problems?
What-So What-Now What
- What? What happened? What did you notice? What facts or observations stood out? Include observations about space, process, emotions you noticed.
- So What? What does the data mean? Why is it important? What patterns or conclusions are emerging? What hunches or hypotheses can you make?
- Now What? What actions or first steps make sense?
SWE-Bench
Go to this issue: pylint 4551
With a partner, read through the logs of the tool I posted to Teams.
June 17: Cost and Defect Estimation
Checkin Exercise
On a piece of paper1,
Explain two concerns you might have in applying the insights from the course project to a new data science project for a private company.
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Plan
- Work on A3 - causal modeling
- Cost Estimation
- Traceability
- Testing
Project notes
Important to show your group’s reflection on the work you and the AI did.
Causal models can be helpful here - what are the other confounds.
e.g. > Predicts if the pull request will be merged by checking if the agent has made successful contributions in the past.
Why would we expect this to be true/false? What other factors might influence the condition “PR was merged”?
Some other explanations
- (specific to this PR)
- the PR solves a problem
- the PR is understandable
- the PR/bug is small and trivial
Still more
- (specific to the agent/human interaction)
- the agent is trusted
- a different, pro-agent person accepted the PR
- (specific to the project)
- the project allows agent contributions
- the agent signed a CLA
Implications for industry and research.
Causal diagrams for A3.
- Explore the dataset .ARFF file.
- Understand the data model: the variables, including dependent and independent variables.
- Create a causal graph of how you think the various variables interact. How will that help you specify the model?
- Without the computer, think about how you should create a likelihood and prior for the distribution of this data. The instructor will remind you what a likelihood and prior are in class.
Estimation Quotes to Affirm and Challenge
Go through the two estimation readings (COCOMO and Agile Effort…).
Find at least one quote that you agree with (AFFIRM) and one quote you wish to CHALLENGE.
Form a group with 3 other students. Discuss the two quotes you found and the reasons you chose them.
Report back to the class with the group’s two chosen quotes.
How does this change in an LLM era?
Estimation
A story point or a COCOMO output is just an estimate of what effort and cost will be required.
Ask an AI about the “no estimates” movement. What is a problem with no estimates?
Defects
- what is “JIT” defect prediction?
- when and how do we do JIT defect prediction? why do we care?
- how can we figure out what a defect-inducing change is?
- Table 5 of the JIT paper and what “change level” is - vs JS specific. What is the intuition here?
- why do we want to do “transfer learning”?
- what is “data hungry” approaches?
- what is the gist of the early vs late distinction? The “first 150 commits” - why?
June 17: Testing and Out Of Sample
Web App Out of Sample Exercise
Web app exercise cont
One example: https://github.com/vuejs/core/pull/13550 and https://github.com/facebook/react/pull/30451 both deal with whitespace issues.
- Pretend you and your group are building a Data Science tool to help with PR assignment. What elements of each project will make it:
- Harder to generalize your results?
- Easier to generalize your results?
- Report back.
June 17: Traceability and Clones
Clones Exercise
I’ve uploaded two files to the Teams channel. Each contains a method pair that might be a clone.
With a partner,
- load all files into your IDE
- read over them so you understand what they do.
- identify which pairings, if any, are clones, and why you say that.
- Ask an AI tool what it thinks.
- for the clones, identify which type they are
June 24: Qualitative Coding
Checkin Exercise
On a piece of paper1,
According to Agrawal, what is “wrong” with topic modeling?
Make sure your name and V# are clearly on the paper. Hand this in at the end of class.
Plan
- LDA walk through
- Coding exercise
Unstructured Text
- what we look at today is how to make sense of unstructured text.
- Where does this occur in the AIDev dataset?
- what options do we have to process this?
Aside: How Do Humans Make Sense of the World?
in other words, when we see a statement like
“added brief extra details for other potential situations.”
what are we understanding? How do we characterize this?
Levels (thanks to Aranda)
- a commit message / SO question edit / instant message on Slack (context missing)
- part of a conversation
- hinting at org. context
- depends on the writer’s context (feelings that day, posture for bosses, …)
LDA
LDA = Latent Dirichlet Allocation
Why LDA
- Fast
- Identify common patterns - clusters
- Stochastic yet predictable
Coding Practice
We have data on change rationale from people who edited StackOverflow (SO) questions. Questions can be edited by moderators or the original asker.
We want to know “Why do people edit a SO question?”?
- I’ve added 14 CSV files to the teams channel.
- Pick one of the files to work on, corresponding to your Brightspace group ID.
Coding Exercise
- Read each row entry, using
- your prior understanding of SO,
- the link to the question in the CSV, and
- the text itself
- assign a short label to each of the ten entries by yourself.
- Then check your labels with the ones your group added.
- Now run the 10 entries through the GenAI tool of your choice.
Coding Reflection
- did you and your colleagues agree? Where and why?
- what value did the LLM add?
- what is your assessment of why people edit these questions?
June 26: Posters
Plan
- Poster presentations

← Course Home©️ Neil Ernst