Effectively using AI in SE
2025-07-29
Caveats
- I am learning as I go, as you are.
- Things have moved fast, and there are many tools to choose from.
- More effective models tend to cost more.
- I don’t believe AI will replace thinking.
Vibe Coding

Vibe Coding
Let’s try an exercise.
- Go to your favorite GenAI tool.
- Write an app that uses animated HTML to create a DVD box that moves around the screen.
- Just use any prompt you wish.
- Take 5 minutes and we will check some of the solutions together.
GenAI and Programming and Data Science
In what ways is GenAI transforming this field? What should we do in this class in response?
How I use it:
- to answer questions for background I forgot or didn’t know
- to write scripts to manage notes and marks
- to code up answers to the exercises to test my questions
I do not use it to mark your assignments, tempting as that is.
Policies
See the course README file and the University position statement.
How to Use AI as a Student
(from https://substack.com/home/post/p-160131730)
Emphasize craftsmanship. AI rewards having a structured, careful development process:
- Thinking hard and chatting about the problem and the changes you need to implement before doing anything
- Keeping components encapsulated with carefully-designed interfaces
- Controlling the scope of your changes; current AIs work best at the function or class level
As A Student (2)
- Testing and validation; how do you know your program works
- Good manual debugging skills (this was a major takeaway from the class - students found AI debugging to be unreliable)
- General system knowledge: networking, OS, data formats, databases
Shopify’s approach (and others, like MSFT)

Useful guides for using LLMs
- https://rtl.chrisadams.me.uk/2024/12/how-i-use-llms-neat-tricks-with-simons-llm-tool/
- all and any of Simon Willison’s writing
Accessible tools (financially)
Break
Exercise: Use LLMs
Exercise: Use LLMs
We will do what Andrej Karpathy calls “vibe coding”: a zen-like use of autocomplete to try and get the AI to do something useful.
Kent Beck has this nice model of how this works. You add features, hurting modularity, then get the modularity - the options - back.
Exercise: Steps
- Download this data file: https://github.com/datasciencedojo/datasets/blob/master/titanic.csv
- Setup an AI tool. I am showing
gemini. - Get the AI to parse the data file and show simple descriptive stats in an R notebook.
- Display the graph.
Vibe Coding Vs AI-assisted Engineering
vs “Augmented Coding” (Kent Beck)
| Vibes, man | Augmented |
|---|---|
| ‘continue monkey’ | Testing |
| ‘Don’t look at code’ | Security |
| ‘Let it rip’ | Maintainability |
| ‘Keep Going!’ | Reliability |
| ‘YOLO’ | Correctness |
| Performance and scaling |
via Gergely
Adding Context
What Is Context?

context venn diagram via https://www.philschmid.de/context-engineering
Building Good Prompts
As Simon Willison writes,
The entire game when it comes to prompting LLMs is to carefully control their context—the inputs (and subsequent outputs) that make it into the current conversation with the model.
So how can we do that?
The Challenge
An LLM is trained on vast amounts of general data, like all of Wikipedia and all of GitHub.
But our problem is a particular one, and we don’t know if the LLM’s distribution matches ours.
So we need to steer it to the space of solutions that apply to us.
Another term for this is context engineering1
Quote
+1 for “context engineering” over “prompt engineering”.
People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting […] Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits. […]
Context Issues
(derived from the article here)
Context is not free… every token influences the model’s behavior.
- Context Poisoning: When a hallucination or other error makes it into the context, where it is repeatedly referenced.
- Context Distraction: When a context grows so long that the model over-focuses on the context, neglecting what it learned during training.
Issues (2)
- Context Confusion: When superfluous information in the context is used by the model to generate a low-quality response.
- Context Clash: When you accrue new information and tools in your context that conflicts with other information in the prompt. 1
Tactics for improving Context
- Use RAG
- Be Deliberate in Tool Choice: More tools is not better.
- Context Quarantine: Use sub-agents to isolate (modularity!)
- Prune the context: use a tool to remove unnecessary docs
- Summarize: give the model the summary, not everything.
- Offload: don’t put everything into the context.
Context and RAG
Adding Context With RAG
A lot of the challenge with software engineering is understanding what the current program is supposed to be doing—what Peter Naur called the “theory” of the program.
The LLM is no different. We need to tell it what to do.
Two Problems
- LLMs are limited to the data they are trained on (e.g., mostly English texts, wikipedia) as of a given date.
- They exude confidence in their answers and have no way of knowing “truth” -> hallucinations.
RAG aka Prompt-Stuffing
RAG: try to figure out the most relevant documents for the user’s question and stuff as many of them as possible into the prompt. – Simon Willison
- Simon’s example: Stuff a lot of Python docs into the prompt, and now the LLM ‘knows’ that info.
- Super helpful for giving local context, especially for documents the LLM might not have seen (proprietary docs).
How?
Combine well understood information retrieval approaches with transformers to condition the result on the document set.
How? Math intuition
Given input sequence \(x\), and text documents \(z\), we want to generate output sequence \(y\).
- Use a retriever \(p_\eta(z|x)\) with parameters \(\eta\) that returns distributions over text passages given a query \(x\).
- Use a generator \(p_θ(y_i|x,z,y_{1:i−1})\) parametrized by θ that generates a current token based on a context of the previous \(i−1\) tokens \(y_{1:i−1}\), the original input \(x\) and a retrieved passage \(z\).
- Marginalize over the probabilities to produce the most likely answer \(z\).
Intuition
- Vanilla LLM can produce K sequences to our question (e.g., “what university is best for CS in Canada?”).
- We typically cut off the sequences at a threshold (ultimately so K=1).
- The rank of the K answers will reflect training data (e.g., universities like UofT with the most documents about them).
- If we apply RAG, we can bias the rankings according to the provided RAG documents (for example, a bunch of internal documents from CSCAN discussing computer science departments).
- The selected sequence (\(y\)) will be a weighted combination of the final sequences.
Discussion
Why does this work?
Tools
Testing Prompts and Outputs with Evals
Creating Effective Evals
An eval is a test that the AI’s output is doing what you had hoped. It isn’t a unit test exactly, since unit tests are repeatable and deterministic (ideally). But an eval should give you a sense that the output is what you expect.
Q: What is an eval for a data analysis project?
PromptFoo
This is an emerging space. One approach is described here.
It uses the PromptFoo tool to manage the workflow.
Assertions
The idea is that you
- prompt the LLM to do something (e.g., generate code),
- it returns a result, and then
- the eval is used to examine if the LLM did the right thing. If not, you
- change the model
- add context via RAG or MCP or
- redo the prompt.
Assertions (2)
Key to eval is the assertion for what the model should look for. In PromptFoo there are several types of assertions 1
“Assertions”
- Deterministic
- contains
- equals
- perplexity
- levinshtein
- regex
- …
Assertions
- Model-graded (we use another LLM to judge)
- llm-rubric
- select-best
- …
Assertions with PromptFoo
The model-graded assertions take a prompt to the LLM that will judge the output. E.g., select-best might say “choose the most concise and accurate response”. Now, whether the other LLM will do that is subject to that LLM’s performance (you can see the recursion here).
A .yaml file holds all the evals for a given problem. This Google sheet gives some examples for an application that tries to parse government websites for food assistance.
Example assertions
**capability**: It gives accurate advice about asset limits based on your state
**question**: I am trying to figure out if I can get food stamps. I lost my job 2 months ago, so have not had any income. But I do have $10,000 in my bank account. I live in Texas. Can I be eligible for food stamps? Answer with only one of: YES, NO, REFUSE.
**__expected**: contains:NO
Eval Exercise
- Install and Configure PromptFoo.
- Select your preferred AI tool.
- We are creating a system that will use an LLM to give us updated information on how to use MongoDB.
- Create 2 capabilities the LLM should give users, two prompts users might ask, and the PromptFoo validation criteria using assertions.
- Then run this example.
Evals - How To Make It Effective
What do you need to develop these evals?
- domain expertise: it helps to know the correct answer. In the sample, that means comprehensive knowledge about food stamps, US federal and state laws and regulations, acronyms, legal cases, etc.
- sense for how often things might change
- cleverness at writing prompts and assertions. This is an art, not a science.
- costs $$ to run against different models!
Tool Use and Agents
- Call other programs to do stuff, some of which are other GenAI calls.
- E.g. rather than asking the LLM to add 2+2, just say “python -c ‘print(2+2)’”
- Gets more interesting when we pre-specify prompts for LLM calls
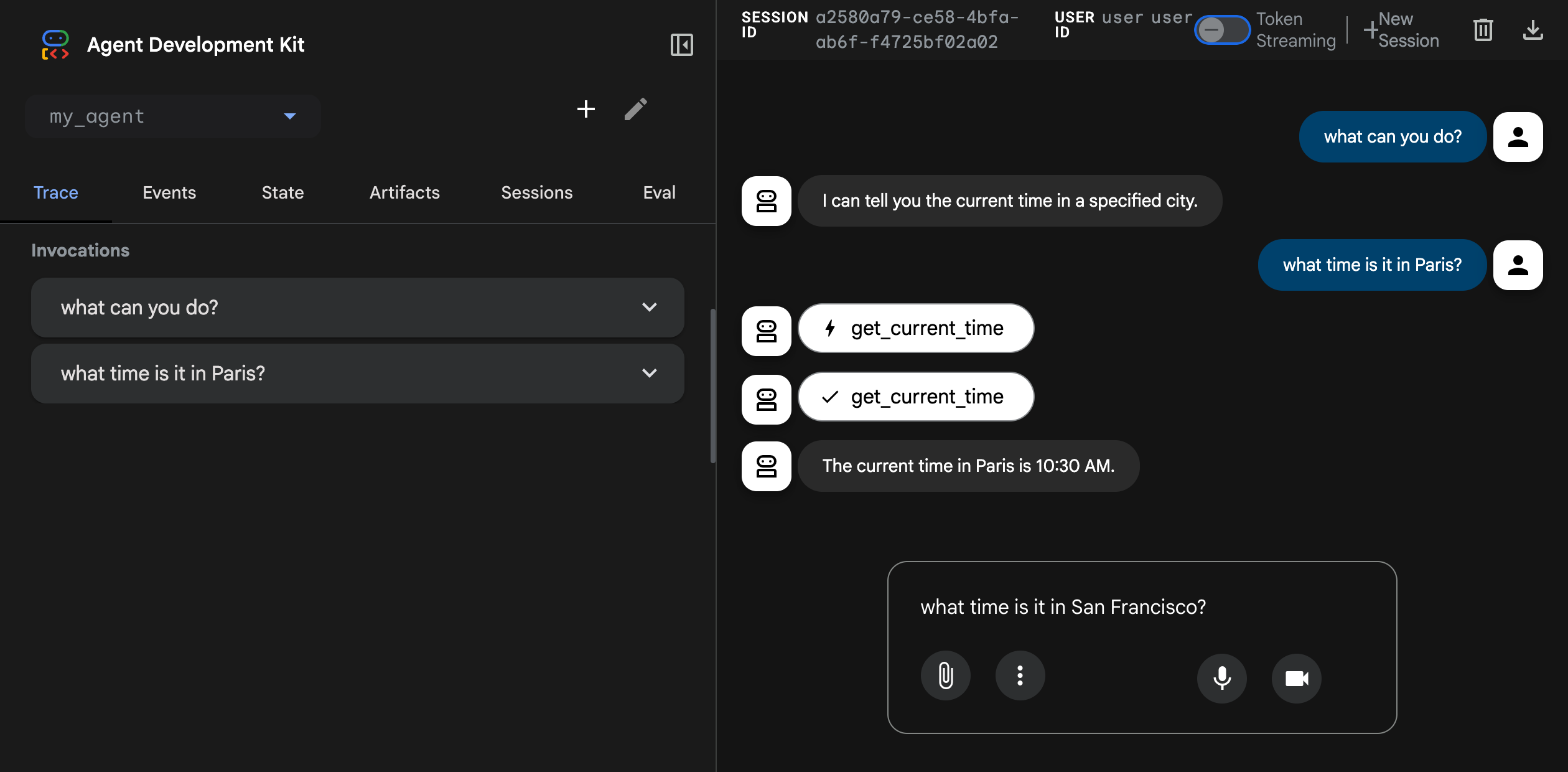
- Let’s look at Google’s framework
root_agent = Agent(
name="weather_time_agent",
model="gemini-2.0-flash",
description=(
"Agent to answer questions about the time and weather in a city."
),
instruction=(
"You are a helpful agent who can answer user questions about the time and weather in a city."
),
tools=[get_weather, get_current_time],
)
Talking to Others with MCP
Overview
Problem: I don’t want the AI to speculate on how to access my API - I have a precise set of calls it can use.
I don’t want it to reinvent regular expressions – just use sed, grep, awk etc.
How to tell the AI what is available? Need to connect it to the API so it can discover what is possible.
NEVER try to edit a file by running terminal commands unless the user specifically asks for it. (Copilot instructions) 1
MCP
MCP solves this problem by providing a standardized way for AI models to discover what tools are available, understand how to use them correctly, and maintain conversation context while switching between different tools. It brings determinism and structure to agent-tool interactions, enabling reliable integration without custom code for each new tool” 1
Other topics to discuss
- What becomes of SWE, SDET, Principal SE roles?

Neil Ernst ©️ 2024-5